Ecto Tips: UUID Boilerplate, Docs, and Composing Changesets
Published on 2020-01-19
I use Ecto Changesets a lot– a TON! and I love them. Since I’ve been using them for a couple years now, I’ve noticed some patterns and now I have a couple tips to share.
Extract Boilerplate
I use UUIDs for all my IDs, specifically v4.
Long ago I managed some legacy codebases that chose (defaulted) integer-based IDs, and two times now I’ve had to migrate them to tables with a BigSerial as the ID because we reached our limit of IDs for the table. It’s easy to forget.
I’d be fine with BigSerial, but since I started using Ecto, I found myself using UUIDs instead, and now it’s become a habit.
What about showing UUIDs in URLs in basic CRUD endpoints?
Yea, it’s really ugly to show UUIDs in the browser URL bar, especially for nested routes. But, should you show internal database IDs to users? I don’t think so, so when using UUIDs I am constantly reminded to design towards generating unique slugs for UX. If you see a UUID in the browser URL, I feel like I should replace it with a human-readable unique slug instead. IDs are for machines, slugs are for humans. URLs are for humans too, though I understand some may not agree with that.
Let’s default to UUID in Ecto
There’s some configuration for Ecto to default to UUIDs:
Then lastly, we’ll wrap that up and make it easier by pulling it into a macro
Configure Generators
If you’re using Phoenix and use its generators, you might care about this
section. When you run mix phx.gen.schema ARGS, Phoenix and Ecto will throw in
some boilerplate into your schemas and migrations. Even if you don’t, it’s
harmless to configure it just in case things change later, or other developers
on your project choose to use the generators.
#./config/config.exs
config :my_app,
ecto_repos: [MyApp.Repo],
generators: [binary_id: true]
# This will tell your Schema that the primary_key is a binary UUID:
#./lib/my_app/random_schema.ex
@primary_key {:id, :binary_id, autogenerate: true}
@foreign_key_type :binary_id
schema "my_table" do
# ...
endConfigure Migrations
When creating tables through a migration, you’ll need to specify that it should
not create an ID column that generates it’s own IDs (more on this later).
Instead, we’ll supply our own primary key column called id.
defmodule MyApp.Repo.Migrations.CreateUsers do
@moduledoc "Creating Users in the database"
use Ecto.Migration
def change do
create table(:users, primary_key: false) do
add :id, :binary_id, primary_key: true
timestamps()
end
end
end
In Ecto 3.x, you can also reconfigure default ID column
settings
with :migration_primary_key so you wouldn’t even have to add :id yourself,
but unfortunately it does not play well with Ecto macros that I will end up
using since it’s via Mix config.
Configure Schema
If you’re using the generators above, then they should insert these options in for you, but if not, you’ll need to make sure they’re present.
defmodule MyApp.RandomSchema do
use Ecto.Schema
import Ecto.Changeset
@primary_key {:id, :binary_id, autogenerate: true}
@foreign_key_type :binary_id
schema "users" do
field :name, :string
timestamps()
end
end
That’s it! It should work. Ecto’s schema macro will use the module attributes
to configure how it should treat the primary key. The documentation has more
information if you want to read more.
Pull Into Macro
That’s a lot of boilerplate for each schema. Let’s make it easier. Notice at
the top of the schema definition? use Ecto.Schema.
This injects some code into the module. We can do that too! Let’s create our own schema file that injects our boilerplate.
defmodule MyApp.Schema do
@moduledoc "Ecto Schema Helpers"
defmacro __using__(_) do
quote do
use Ecto.Schema
import Ecto.Changeset
@primary_key {:id, :binary_id, autogenerate: true}
@foreign_key_type :binary_id
end
end
enddefmodule MyApp.RandomSchema do
- use Ecto.Schema
- import Ecto.Changeset
-
- @primary_key {:id, :binary_id, autogenerate: true}
- @foreign_key_type :binary_id
+ use MyApp.Schema
schema "users" do
field :name, :string
timestamps()
end
endNow for each of your schemas, use this new module and you don’t have to remember the boilerplate anymore.
DB-Generated UUIDs
Maybe you noticed above that we have autogenerate: true above. This is telling
Ecto to generate those ID UUIDs instead of the database. That bothered me; I
feel like that’s a database responsibility, not an app responsibility.
Let’s move that into the database. I’m using PostgreSQL, but I’m sure there are similar tools for other databases.
Enable pgcrypto
Postgres unfortunately cannot generate UUIDs simply out of the box, but it does ship with functions that you can enable. You can get away with creating a function that’ll generate UUIDs, but I prefer some battle-tested code that ships with postgres contrib.
One of those extensions is pgcrypto which supplies a function
gen_random_uuid().
Let’s create a migration to have Postgres enable the extension.
$ mix ecto.gen.migration add_pgcryptodefmodule MyApp.Repo.Migrations.AddPgcrypto do
@moduledoc "Add PgCrypto so we can have Postgres generate it's own IDs"
use Ecto.Migration
def change do
execute(
"CREATE EXTENSION IF NOT EXISTS \"pgcrypto\"",
"DROP EXTENSION IF EXISTS \"pgcrypto\""
)
end
endThis sometimes requires special permissions on the database user. If this doesn’t work for you, then you might need an additional procedure to enable the extension for you. However, this should work for your local database for development.
Use pgcrypto
Now that the database can generate UUIDs, let’s use it our ID columns!
First we’ll tell ID column to default its value. Looking at our earlier migration, let’s modify it.
defmodule MyApp.Repo.Migrations.CreateUsers do
@moduledoc "Creating Users in the database"
use Ecto.Migration
def change do
create table(:users, primary_key: false) do
- add :id, :binary_id, primary_key: true
+ add :id, :binary_id, primary_key: true, default: fragment("gen_random_uuid()")
timestamps()
end
end
endNow it’ll generate it’s own ID. If you stopped here, you’ll notice that when you insert records with Ecto, none of your returned structs will have an ID! What happened?!
We need to tell Ecto to read the ID back into the struct after
writing.
Thankfully, that’s easy. Earlier we pulled some boilerplate into a
MyApp.Schema; let’s modify it:
defmodule MyApp.Schema do
@moduledoc "Ecto Schema Helpers"
defmacro __using__(_) do
quote do
use Ecto.Schema
import Ecto.Changeset
- @primary_key {:id, :binary_id, autogenerate: true}
+ @primary_key {:id, :binary_id, read_after_writes: true}
@foreign_key_type :binary_id
end
end
endNow Ecto will pull the database-generated UUID back. Yes! Now we have IDs generated in the database again.
Avoiding Collisions
Ok, so it’s works, but what happens in the low low chance that it generated a duplicate UUID? It will fail to insert since the primary key is unique. In this case, you’ll need to handle retrying with application code to retry once. The probability of it failing a second time is galaxy-scale low. Probably not worth handling in new code for smallish tables, and worth revisiting if you have very large-scale tables in the millions or billions.
Have Elixir Write Docs For You
One tedious task I find myself doing is trying to remember what fields I need, don’t need, and which ones have a default value if not supplied when interacting with a changeset function. I’ll constantly flip back and forth between my forms, contexts, and schemas.
In VIM, I’m using coc.nvim to enable Language Server integration. You can do this easily in VSCode as well. One of the great features of this is that you can lookup the documentation on a function with a keypress or hover.
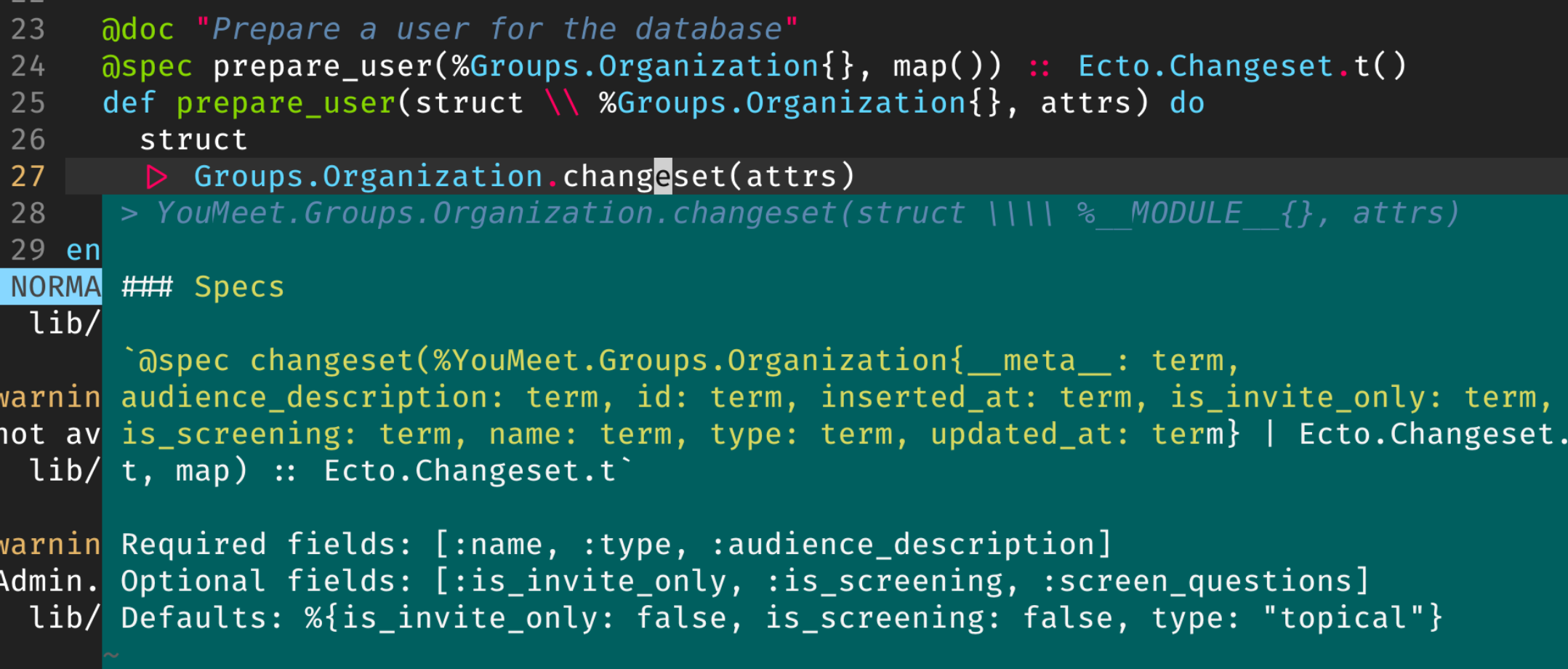
See the screenshot and how it’s listing out the required, optional, and default fields? Let’s make that happen.
defmodule MyApp.RandomSchema do
@moduledoc "The Random Schema."
use MyApp.Schema
@defaults %{
type: "topical",
is_invite_only: false,
is_screening: false
}
schema "organizations" do
field :name, :string
field :type, :string, default: @defaults[:type]
field :audience_description, :string
field :is_invite_only, :boolean, default: @defaults[:is_invite_only]
field :is_screening, :boolean, default: @defaults[:is_screening]
timestamps()
end
@optional_fields ~w[is_invite_only is_screening screen_questions]a
@required_fields ~w[name type audience_description]a
@doc """
Required fields: #{inspect @required_fields}
Optional fields: #{inspect @optional_fields}
Defaults: #{inspect @defaults}
"""
@spec changeset(%__MODULE__{} | Ecto.Changeset.t(), map()) ::
Ecto.Changeset.t()
def changeset(struct \\ %__MODULE__{}, attrs) do
struct
|> cast(attrs, @optional_fields ++ @required_fields)
|> validate_required(@required_fields)
end
end
It’s not hard at all! It’s a feature I often forget exists with ExDocs and
Elixir: you can interpolate compiled values into documentation. In this case,
I’m defining my @optional_fields, @required_fields, and @defaults, and
then interpolating them into the changeset docs.
Easy peasy!
Compose Changesets
Did you know that changesets can chain together?
For example:
Let’s say you have a “main” changeset that performs the basic validations. These validations should occur every single time an insert or update occurs for this schema. This happens for both admins and users.
Let’s also say that you have another changeset that runs additional validations if the User is updating the record versus the Admin updating the same record. You don’t have to duplicate that code!
# In MySchema
@spec changeset(%__MODULE__{} | Ecto.Changeset.t(), map()) ::
Ecto.Changeset.t()
def changeset(struct_or_changeset \\ %__MODULE__{}, attrs) do
struct_or_changeset
|> cast(attrs, @optional_fields ++ @required_fields)
|> validate_required(@required_fields)
end
@spec additional_restrictions_changeset(%__MODULE__{} | Ecto.Changeset.t(), map()) ::
Ecto.Changeset.t()
def additional_restrictions_changeset(struct_or_changeset \\ %__MODULE__{}, attrs) do
struct_or_changeset
|> changeset(attrs)
|> more_validations()
end
@spec user_changeset(%__MODULE__{} | Ecto.Changeset.t(), map()) ::
Ecto.Changeset.t()
def user_changeset(changeset, attrs) do
changeset
|> cast(attrs, [:some_more_fields])
|> even_more_validations()
end
## ... In some other app code
def create(params) do
MySchema.changeset(%MySchema{}, params)
end
def restricted_create(params) do
MySchema.additional_restrictions_changeset(%MySchema{}, params)
end
def user_create(params) do
%MySchema{}
|> MySchema.changeset(params)
|> MySchema.user_changeset(params)
end
This way, you can use additional_restrictions_changeset/2 by itself and get
all the same logic within changeset/2. Or alternatively, compose them together
from the outside like in user_create/1
A common mistake that prevents changesets from being composable is that we’ll write our function signatures to require the struct as the first param:
# don't do this:
@spec changeset(%__MODULE__{}, map()) :: Ecto.Changeset.t()
def changeset(%__MODULE__{} = struct, attrs) do
struct
|> cast(attrs, @optional_fields ++ @required_fields)
|> validate_required(@required_fields)
endThis makes it more restrictive and keeps it from being composable.